
Consulting / SI 異なるアプローチ
ビッグデータ分析
今日のビッグデータは、初期段階においてシステムへの非常に高価な投資と高い人的資源のコストを負わされており、具体的に進行中のオーバーヘッドの費用も企業にとっては負荷と見られます。初期投資から生産分析までの設置時間は6ヵ月から1年以上まで広がりクエリー反応の待ち時間は数日もしくは数週間となっています。
『現在は、ゼロから物を創る我々の過去の経験と比べて、お客様に使用状況のメトリックを提供する上で市場投入までの時間が短縮されました。またフルタイムのシステムエンジニアを関連する基盤を維持するために雇うより、経費は非常に低くなりました。』
Spulurgy社 創業者 Michi Kono氏
異なるアプローチ
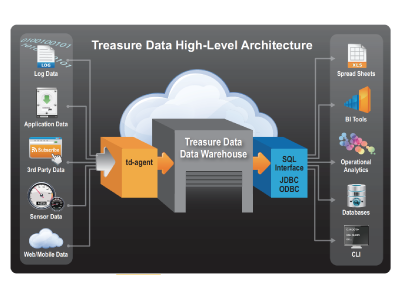
Treasure Dataは、オープンソースのHadoopの力とクラウドサービステクノロジーの革新を合わせて使います。このユニークな組み合わせは、
- 複雑な分析クエリへの回答時間を数ヵ月から数日に圧縮します
- 甚だしい複雑さと設置から生産へのサイクルの時間を削減します
- オーバーヘッドの費用を無くすか、削減します
- ビッグデータのウェアハウスを持つための前払いのインフラコスト
- 特別な技術を持ったスタッフを設置する費用
Treasure Dataを使えば、大規模なデータをアップし、保存し、維持管理するためにオープンソースソフトに基づいた革新的なデータマネジメントと分析技術のアドバンテージを活用することができます。同時に、Treasure Dataはこれまでのデータウェアハウスのアプローチに典型的だったコストと複雑さを回避するので、ユーザーはリソースをビジネス分析にフォーカスさせることができます。
これ以降は、Treasure Dataの主要な構成要素と利点を要約します。
ビルトインの標準化されたデータ・コレクター
Treasure Dataは十分にサポートされたfluentdのデータ・コレクターを提供します。この堅牢なアップロードデーモンはそれぞれのデータソースにインストールされ、データストアに対してバッチ処理と継続的なデータフィードを提供します。
コレクターは複数のメリットを提供し、fluentdは構造化、半構造化、構造化されていないデータ形式のための標準的なJSONのフォーマットをサポートしています。
アウトプットは機械が読み取れるだけではなく、人間にとっても直感的に分かるものとなっています。ETLのルーチンは簡単に作られ、一貫し、管理のオーバーヘッド費用を変えることを助け、コレクターは複数の同時発生のターゲットにロードする高度な並列バッチとそれに続くロード時間を削減しリアルタイムに近いかもしくはイベントベースの分析を可能にする継続的なフィードをサポートします。
より重要なことは、コレクターはより適合しやすく、革新しやすくするためにオープンソースのソフトウェアとして提供されています。
高度化した コラムナ(行)型のデータストア
アーキテクチャーは革新的なコラムナ(行)型のSTOREを含むようにHadoopのスタックを拡大しており、HDFSと型通りのデータベースエンジンの核となるパフォーマンスと管理問題を扱います。データストアはクエリーの呼び出し時間のターゲットデータのスキャンに非常な効率性を提供し、他の実行システムとは違ってそれぞれのクエリーに完璧なレコードを出してくるというよりはむしろ関連するカラムでのみ作動します。
これらの特徴はクエリータイムとオーバーヘッド費用の処理を削減し、その結果コストも劇的に削減されます。
データベースは低いオーバーヘッドの費用でフルのスキーマの独立をサポートします。この能力はロードサイクルのはじめとアップデートのいずれも劇的に減らします。初期のデータロードはユーザーのデータへの習熟度合によって莫大な時間を浪費します。この時間のほとんどはデータを認識し、フォーマットとスキームを定義するのに使われます。
ロードでの一つのスキーマチェンジが分析を一週間かそれ以上遅らせます。スキーマが独立していればこれらの遅れは無くすことができ、非仮想的な分析をサポートし、クエリーを生み出す際に基本のデータ構造を理解する必要があるアナリストを自由にさせることができます。いくつかのユニークなケースではユーザーは一層パフォーマンスを良くするためにスキーマを事例を挙げて裏付けたいと望むかもしれません。この能力もサポートされます。
並列処理のSQLスタイルのクエリー
よく親しまれたSQLスタイルのクエリーインターフェイスがMapReduceのプログラムの複雑さを緩和するために提供されます。クエリー文はMapReduceの形式に変更され、並列処理をフルサポートするために実行されます。
このおかげでSQLの分かるスタッフは特別なプログラミングスキル無しでこれまでのHadoop環境の中で最大限の力を発揮し、柔軟に対処することが可能になります。加えて、これはクエリー生成のための時間を削減し、データに関する反復対話をサポートします。
ビジネスアナリストやプロの開発者がクエリーを生み出したりブラッシュアップしたりする必要性はなくなります。
query intellectual propertyのための既存の投資はTreasure Dataのシンタックスへシームレスに変更するようにも拡張できます。
リレーショナルデータベースや今までのウェアハウスへのエクスポート
ビルトインされたエクスポート機能はTreasure Dataから今までのリレーショナルデータベースやデータウェアハウスにデータを移すために提供されます。
これによってTreasure Dataを使った大容量データ処理が主たる分析エンジンとしてだけではなく、ビッグデータの分析結果を従来型の企業データウェアハウスでのクエリー/レポートティングアーキテクチャーにどのデータエレメントを含めるべきかを、より適確に識別するためのプリプロセッシングのプラットフォームとしても効率的なものとなります。
ビジネスインテリジェンスツールにとってのJDBCインターフェース
Treasure Dataはビジネスインテリジェンスツールにとっての標準的なJDBCインターフェースとしても提供されます。カスタマイズされたコーディングや初期のデータストアとこれらをリンクさせるためのメンテナンスは無くなります。
これによってTreasure Dataによるビジネス分析は、プロのアナリストが広範囲のビジネスツールを活用して幅広くビッグデータ分析することを可能にします。そしてユーザーは好みのビジネス分析ツールやアプリを使いながら、追加的な分析やレポートKPIダッシュボードの作成などの追加的な作業を行うことができます。
さらに詳しい情報は
お問い合わせ・資料ダウンロード
コンサルティング&SIに関するお問い合わせ
サイオステクノロジーがご提供する製品・サービスのお問い合わせはこちらからお送り下さい。