
Consulting / SI データコレクション
WebのログやIoT/M2Mといった非構造化データのリアルタイムな収集から、ERPやCRM/POSなどRDBMSによる構造化データのバルク転送まで、多種・多様で膨大なデータの収集に対応します。
ビッグデータでは、非構造化データのリアルタイムな収集から、従来のRDBのような構造化データまで、多種・多様で膨大なデータが収集対象になります。
そのために、データの形式や更新頻度に合致したデータ収集の仕組みの構築が不可欠です。
非構造化データの収集では、あらゆる形式のデータを統一的に収集できる仕組みが必要になります。
そこで、オープンソースのデータ収集ツールを利用することで、外部要因の影響を最小限におさえながら、Webログや外部サービスのデータなどを統一的・連続的にインポートすることが可能になります。
構造化データに関しては、データの形式や分量はある程度まとまっていますが、業務システムごとにサイロ化し、データ形式や更新頻度が異なっているのが実情です。
そこで、多様なデータを統合できるアプレッソ社の「DataSpider」などのEAIツールや、基幹系システムなどに蓄積されたデータを抽出・変換・出力するTalend社の「Talend Open Studio」などのETLツールを活用することで、形式や更新頻度の異なるデータを統合することが可能になります。
SIOS BigData One Stop Solution では、このような非構造化データから分散している構造化データまでを対象にして、Treasure Data CDPやAmazon Redshiftなど、クラウド型のビッグデータ基盤と、RDB/EAI/ETLといった従来の企業データ統合の仕組みを最適な形で組み合わせて、データ収集に対応します。
データコレクションの導入支援例
- ログコレクターセットアップ
- bulk importセットアップ
- ロギングモニタセットアップ
- ユーザアプリケーションへのロギングライブラリ組込み支援
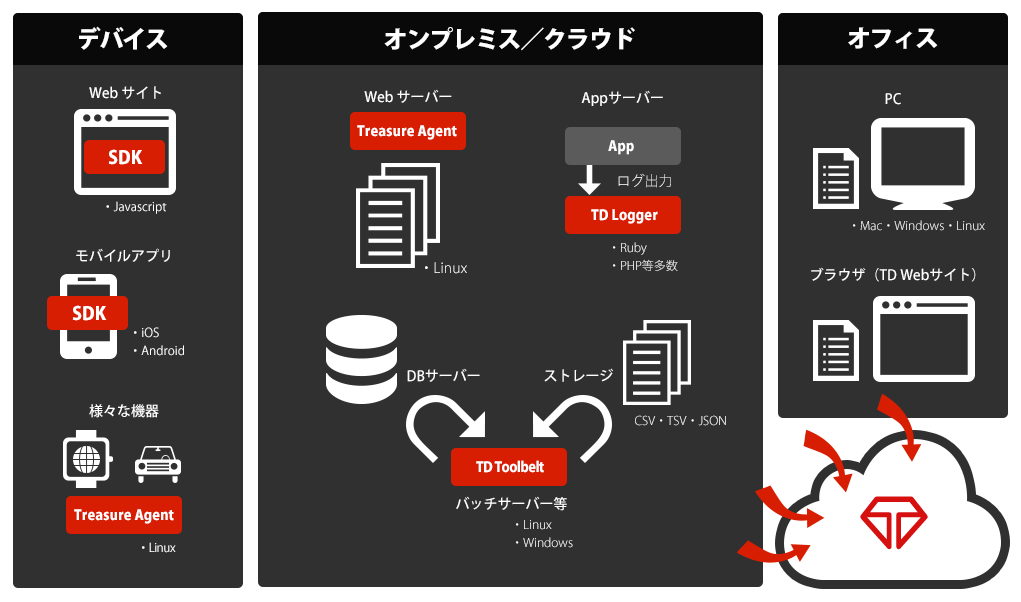
Treasure Dataで利用可能なデータコレクター
お問い合わせ・資料ダウンロード
コンサルティング&SIに関するお問い合わせ
サイオステクノロジーがご提供する製品・サービスのお問い合わせはこちらからお送り下さい。