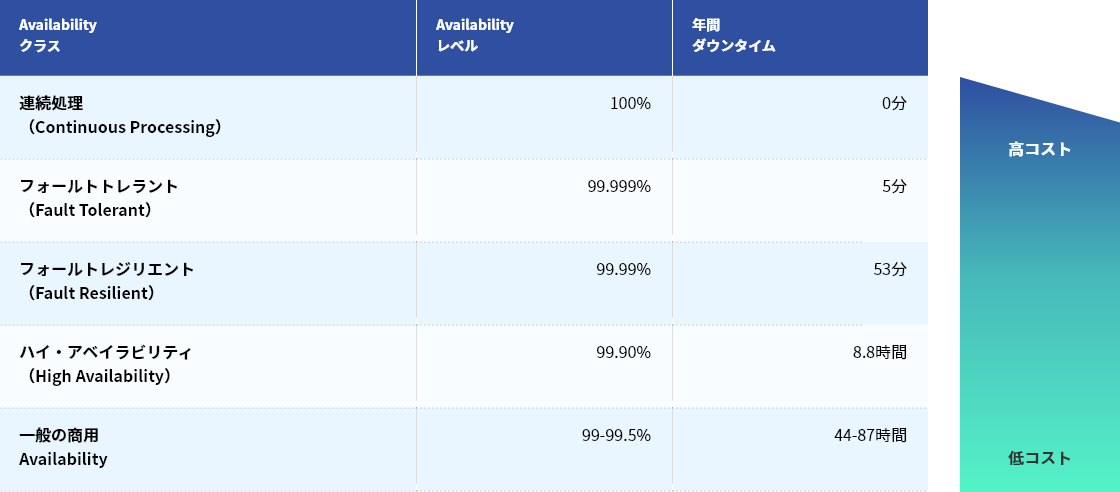
障害対策要件を検討する際、システムが再稼働するまでの時間であるRTO(Recovery Time Objective)とデータを戻す時点であるRPO(Recovery Point Objective)を考慮します。各ポイントを障害直前・直後に近づければ近づけるほど、障害が及ぼす業務への影響を小さくすることができますが、逆に投資額は大きくなります。したがって、システムごとにその復旧要件と、かけられるコストのバランスをとることが大切です。
今回は、RTOを考慮した代表的なソリューションであるHAクラスター(HAクラスタリング)とRPOを考慮したレプリケーションという2つのソリューションを見ていきます。